Monitoring
Monitoring is the runtime operations and observability surface for a single PADAS Core: operators watch live data movement across streams, tasks, sources, and sinks, and pivot into stream diagnostics, live event inspection, PDL querying, and system telemetry without leaving one workspace. It replaces separate Streams-only and Core-only monitoring pages—this is the unified streaming operations console for pipeline health, throughput analysis, and incident response.
The UI combines live telemetry with event visibility: tables expose EPS, drops, and latency; Query and Monitor open runtime stream tooling; the metrics tab charts resource saturation and backpressure-related signals. Together they read like a Kafka-style stream observability layer paired with SIEM-grade runtime diagnostics—grounded in production troubleshooting, not a passive dashboard.
Runtime scope
| Rule | Operational detail |
|---|---|
| Core-local metrics | Every number and row reflects the selected Core only—runtime telemetry is not normalized across engines. |
| Live engine behavior | Readouts come from the running Core’s APIs; Monitoring shows runtime state, not registry intent. |
| Per-Core variance | Throughput, drops, and EPS can differ sharply between Cores; switch the selector to compare—there is no cluster-wide aggregation. |
| No merged topology intent | Graph placement and definitions remain authoritative under Pipelines (registry intent) and Management → Pipelines (assign/deploy); this page answers what is happening now on disk and wire. |
Monitoring workspace
The workspace is a single operational monitoring surface: Streams, Tasks, Sources, and Sinks share one scrollable context so runtime bottlenecks surface faster—ingress pressure, stream congestion, task lag, and sink stalls appear side by side.
- Unified topology visibility — User pipelines and internal streams (metrics, internal, and similar) sit in the same Streams lens so platform runtime observability is visible next to business event flow.
- Core ribbon — Status, uptime, aggregate event volume, engine version, and counts (connectors, streams, tasks) give a pipeline health pulse before you drill into rows.
- Pivot without navigation — Toggle from component tables to the system telemetry view to correlate throughput swings with CPU, memory, and internal counters.
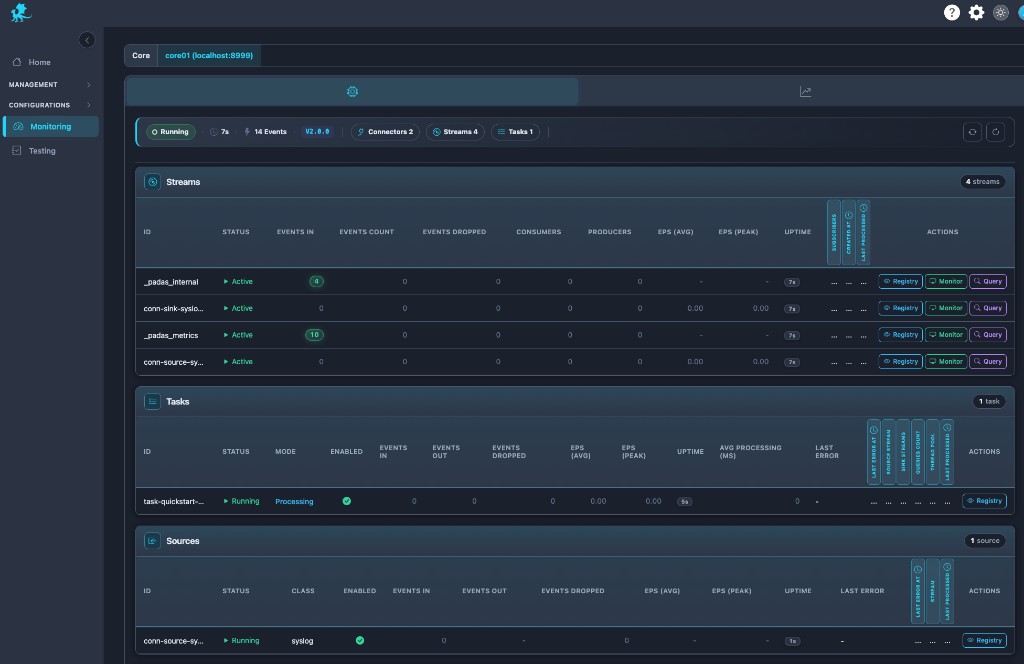
Streams visibility
Streams are the backbone of stream diagnostics: each row shows event flow health—rates, drops, subscriber geometry, and uptime—so downstream pressure and routing mistakes stand out.
- Internal streams — Platform channels appear alongside application streams; they matter for metrics fan-out, control traffic, and explaining “missing” volume during deep dives.
- Producers / consumers — Seeing who publishes and subscribes helps debug stalled consumers, orphaned sinks, or tasks not attached to the stream you expected.
- Congestion signals — Rising dropped events, flattening EPS, or widening ingress vs egress gaps often precede stream congestion or backpressure symptoms—pair with Monitor / Query on the same stream.
Tasks, sources, and sinks extend the same story: task rows expose mode, stream wiring, pool usage, and processing latency; connector rows expose class, enablement, events in/out, EPS, and last error for connector saturation and failure triage.
Runtime metrics
Use row metrics as live telemetry for throughput analysis and runtime troubleshooting:
| Signal | Production interpretation |
|---|---|
| EPS (avg / peak) | EPS collapse after a deploy often flags a failed pipeline slice, blocked stream, or silent connector; sustained low EPS vs peers hints stalled consumers or throttled ingress. |
| Events in / out / count | Throughput imbalance (ingress high, egress flat) suggests downstream congestion or an overloaded task; the inverse may indicate idle sinks or misrouted keys. |
| Dropped events | Abnormal drops plus flat EPS can mean buffer pressure or publish-side rejection; spikes during incidents deserve correlation with system telemetry and connector errors. |
| Avg processing (ms) (tasks) | Elevated latency with stable ingest points to overloaded tasks, hot partitions, or expensive PDL on the hot path. |
| Last error (connectors) | Shortcut to connector saturation, auth, or destination faults before log diving. |
Treat these as runtime metrics that complement—not replace—live event inspection and stream querying.
Querying stream data
Query runs PDL directly against runtime stream data: the editor, time window, refresh cadence, and row limits target the selected stream’s live tail and, where retention allows, historical segments. That makes Query the fastest path for ad-hoc diagnostics during incidents—validate parsers, filters, and eval logic on real traffic without replay tooling.
| Control | When operators use it |
|---|---|
| Run Query | One-shot replay-style investigation over the configured window—ideal for proving a hypothesis on retained or sliding history. |
| Run & Capture | Sampling runs that retain result sets for tickets, comparisons, or follow-up—operational distinction: structured capture of query outcomes vs ephemeral scrolling. |
WAL-backed streams with retention may expose enough history for replay investigation of recent failures; in-memory or short-retention streams emphasize near-live behavior—see Streams for durability expectations.
Results surface as event id, timestamp, and JSON payloads so teams can confirm fields before touching registry definitions.
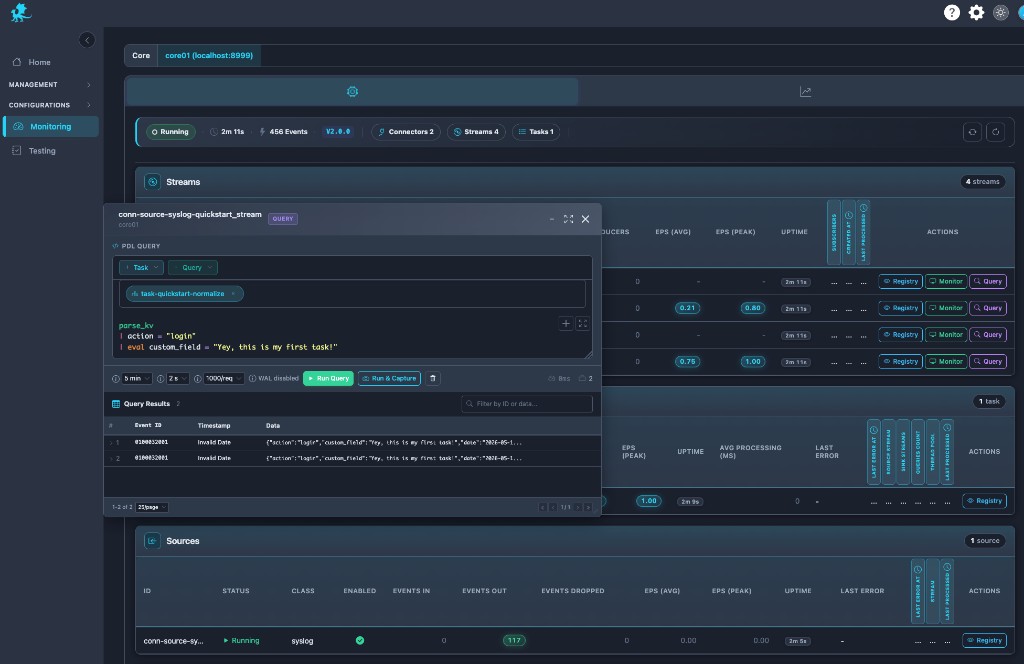
Syntax references: PDL Quick Reference, PDL Reference.
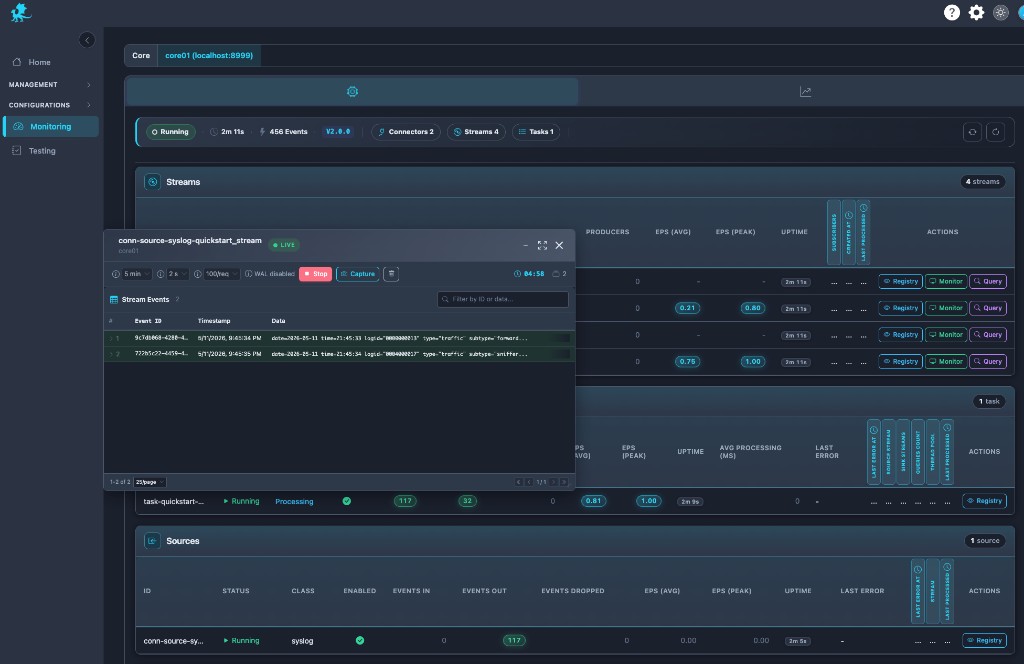
Live monitoring
Monitor delivers near real-time event visibility: a LIVE feed with refresh intervals, limits, stop/start controls, and inline filtering so operators watch bytes-on-wire behavior during rollout validation or parser troubleshooting.
Capture from Monitor (or related controls) seeds Testing with replay datasets—freeze production-shaped events, then iterate PDL in the Testing workspace without mutating live pipeline execution. That connects live stream observability to runtime-safe experimentation; Testing remains its own validation surface, not a nested mode inside Monitoring.
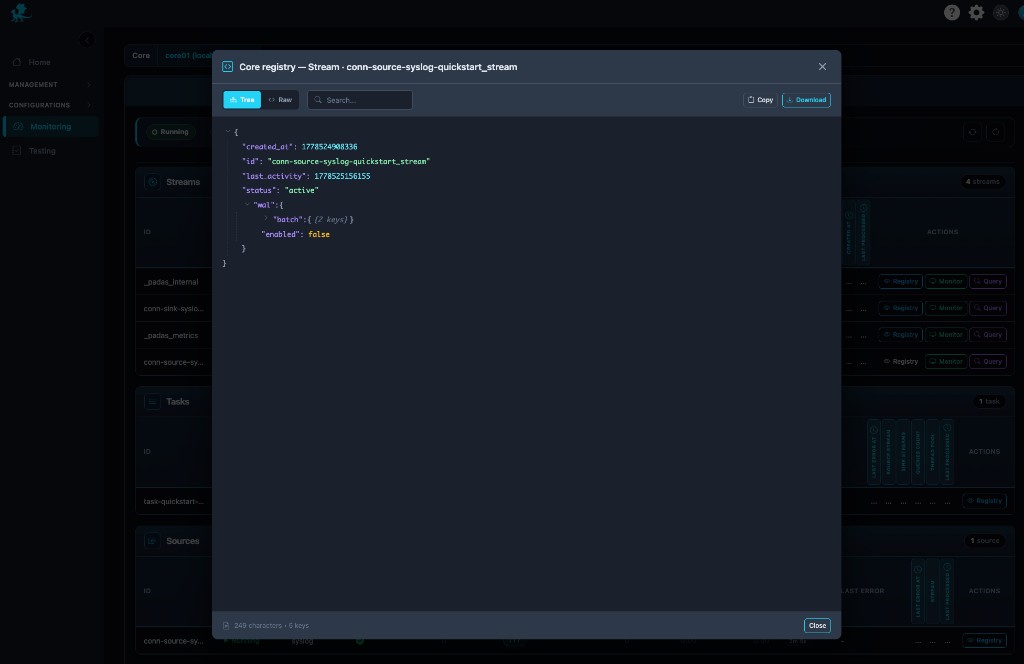
Registry stream inspection
Registry opens runtime registry inspection for the stream row: canonical stream metadata—ids, status, activity timestamps, nested WAL configuration, and related fields—in tree or raw JSON, with search, copy, and download.
Use it when runtime behavior diverges from expectations: verify persistence flags, confirm WAL is enabled/disabled as designed, validate activity timestamps during deployment troubleshooting, or export evidence for change review. It complements Streams by showing what the engine currently materialized, not only what was authored.
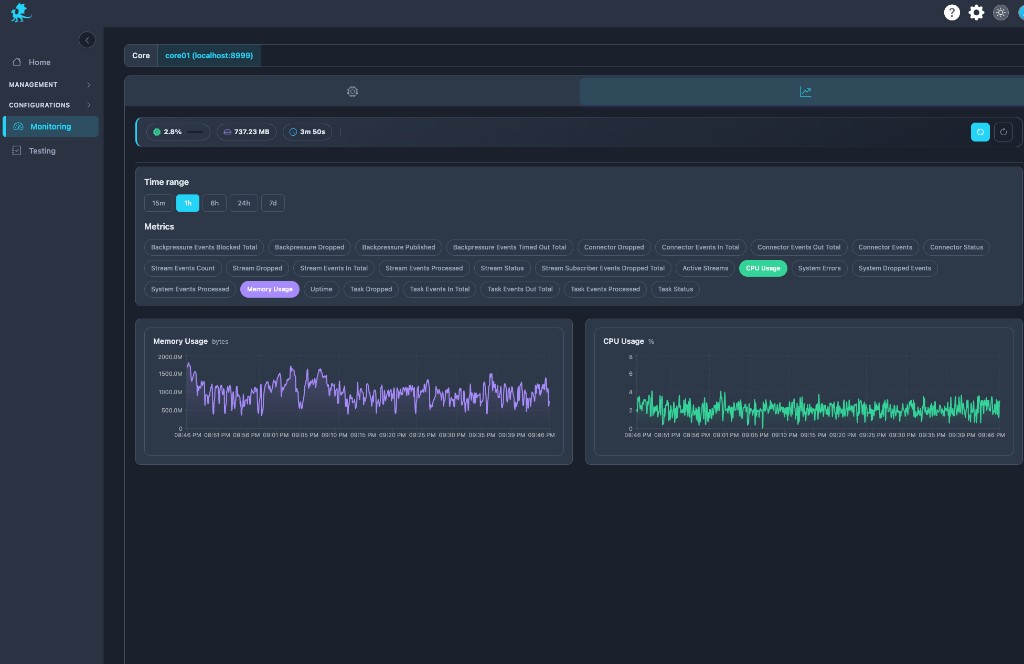
System metrics
The metrics tab is the system telemetry dashboard for the same Core: preset windows (15m–7d), selectable series (CPU, memory, connector/stream/task counters, backpressure totals, processed/dropped aggregates), and synchronized charts for runtime stability analysis.
Operators correlate throughput dips with resource saturation, validate capacity after post-deploy regression windows, and tie stream congestion symptoms to host pressure or Runtime Engine resource limits. This is enterprise-grade observability layered on top of row-level pipeline diagnostics—not “CPU-only monitoring.”
Troubleshooting workflows
Playbooks are maintained centrally in Troubleshooting & Logs → Monitoring and pipeline playbooks.
Monitoring is runtime-focused: it exposes live telemetry, event visibility, and stream diagnostics—it does not author registry objects or deploy topology. Make registry edits under Pipelines and assign/deploy under Management → Pipelines; use Control Tower for graph-level execution controls. Monitoring reflects runtime state, not intended topology alone.
Related pages
- Control Tower — live pipeline graph and graph-level runtime controls
- Testing — replay datasets, PDL validation, capture hand-off from Monitor
- Advanced — Tasks, sources & sinks — runtime start / stop on the selected Core
- Streams — WAL, retention, buffering definitions
- Tasks — task modes and stream wiring
- Pipelines — pipeline topology authoring
- REST API Reference —
/api/v1/*, runtime status - PDL Quick Reference — Query editor syntax
- Core concepts — Observability — metrics and internal streams background
- Glossary — EPS, throughput, runtime diagnostics, internal stream terms